

torch.optim优化算法理解之optim.Adam()
torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来。
为了使用torch.optim,需先构造一个优化器对象Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数。
要构建一个优化器optimizer,你必须给它一个可进行迭代优化的包含了所有参数(所有的参数必须是变量s)的列表。 然后,您可以指定程序优化特定的选项,例如学习速率,权重衰减等。
Optimizer还支持指定每个参数选项。 只需传递一个可迭代的dict来替换先前可迭代的Variable。dict中的每一项都可以定义为一个单独的参数组,参数组用一个params键来包含属于它的参数列表。其他键应该与优化器接受的关键字参数相匹配,才能用作此组的优化选项。
如上,model.base.parameters()将使用1e-2的学习率,model.classifier.parameters()将使用1e-3的学习率。0.9的momentum作用于所有的parameters。
优化步骤:
所有的优化器Optimizer都实现了step()方法来对所有的参数进行更新,它有两种调用方法:
这是大多数优化器都支持的简化版本,使用如下的backward()方法来计算梯度的时候会调用它。
一些优化算法,如共轭梯度和LBFGS需要重新评估目标函数多次,所以你必须传递一个closure以重新计算模型。 closure必须清除梯度,计算并返回损失。
Adam算法:
adam算法来源:Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。其公式如下:
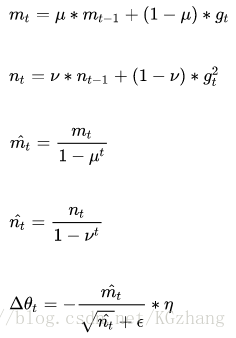
其中,前两个公式分别是对梯度的一阶矩估计和二阶矩估计,可以看作是对期望E|gt|,E|gt^2|的估计;
公式3,4是对一阶二阶矩估计的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整。最后一项前面部分是对学习率n形成的一个动态约束,而且有明确的范围。
参数:
torch.optim.adam源码:
Adam的特点有:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点;
2、对内存需求较小;
3、为不同的参数计算不同的自适应学习率;
4、也适用于大多非凸优化-适用于大数据集和高维空间。


