

最新Python爬虫抖音视频详细教程
大家好!今天给大家带来一个用Python爬取抖音视频的文章,这个文章可能会很枯燥无味。所以先看效果,帅的人现在已经点赞收藏了。
爬取抖音小姐姐的主页所有视频 实现无水印下载
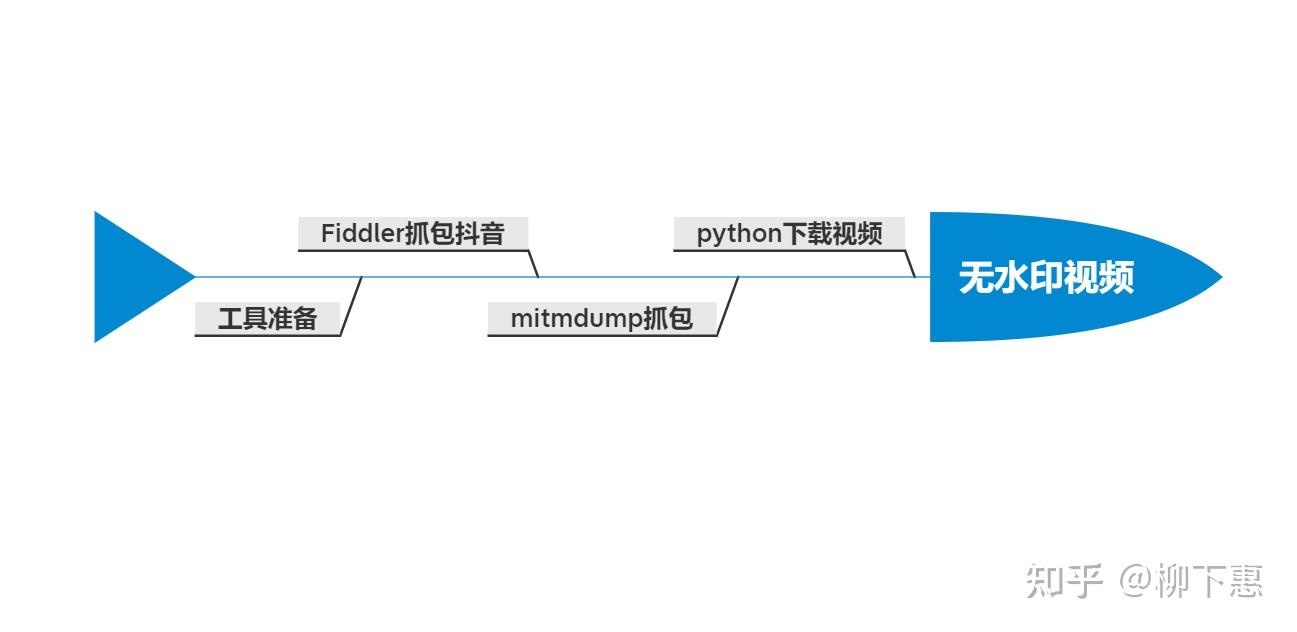
所需工具:1.Pycharm 2.mitmdump 3.fillder 4.夜神模拟器
(1)夜神模拟器配置
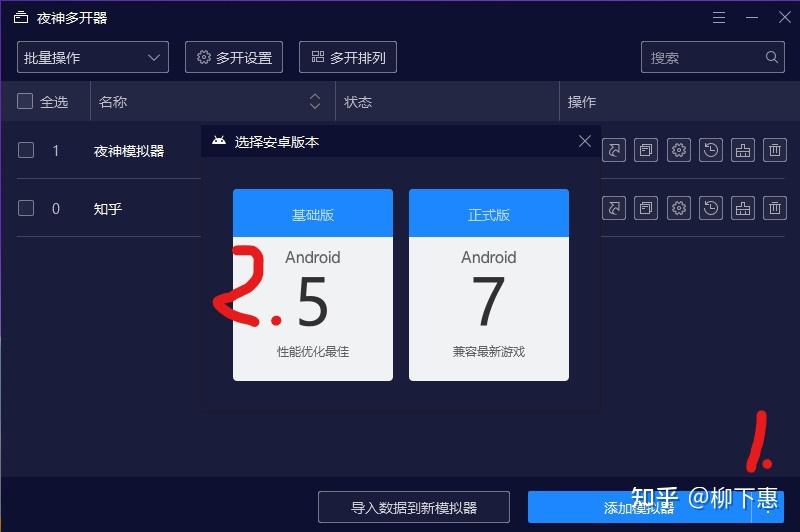
官网下载即可,完成之后打开夜神多开器,创建一个安卓5的模拟器
进入模拟器(开启ROOT后)下载Xposed框架

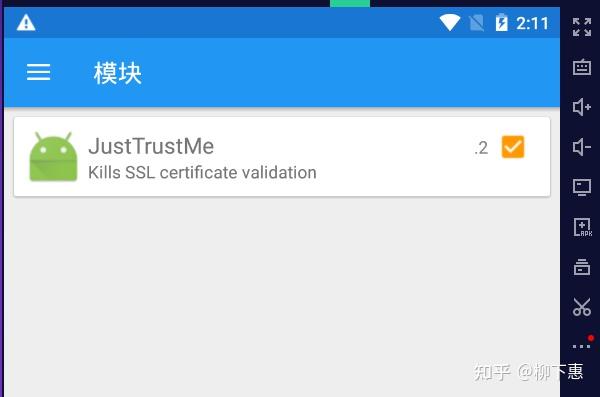
安装模块JustTrustMe
下载抖音,下载抖音版本号:14.8.0(我试过不知道什么原因别的版本抖音不能用)这些东西我都会放在公众号里,回复“抖音视频”即可获得。
(2)fiddler
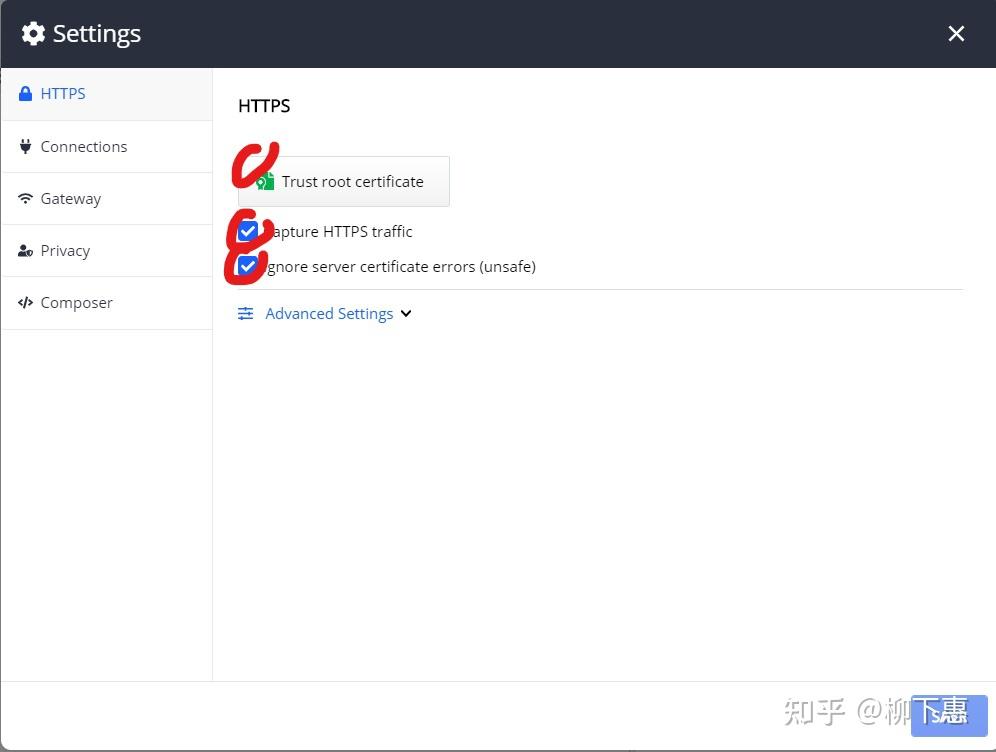
官网下载即可,打开Fiddler会提示注册账号注册就行了,打开Fiddler配置 圈圈的都点一下,端口号可根据自己来 不冲突就行,最后要记得保存

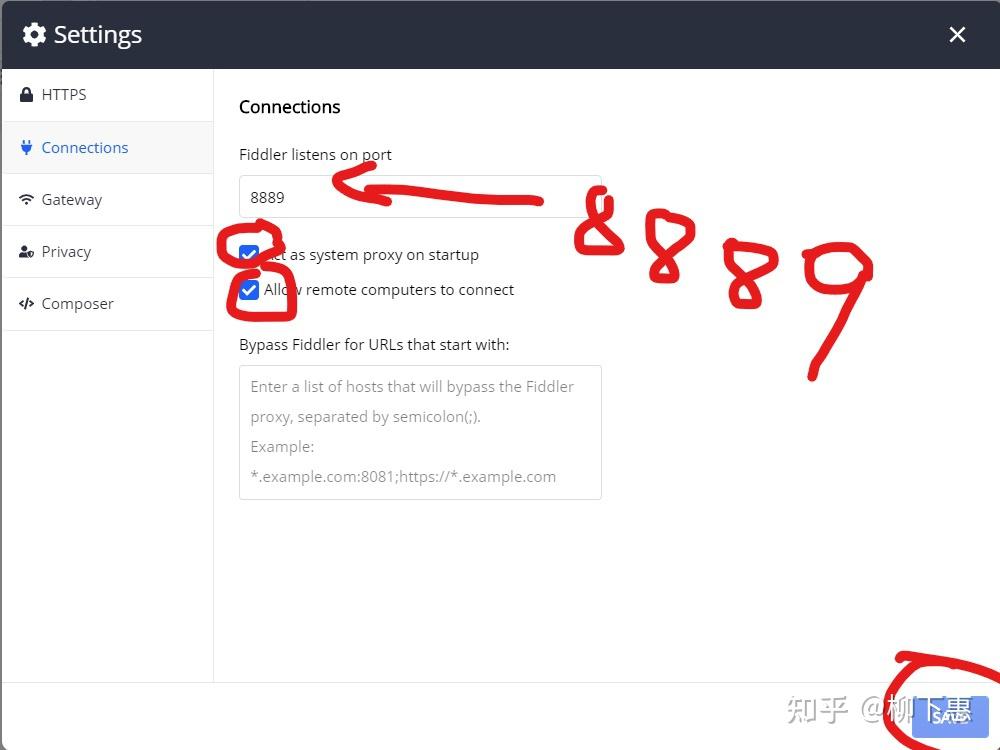
配置手机模拟器中的网络端口号
打开设置——WIFI——长按——修改网络——高级选项——写入自己IP地址和端口号
端口号一定要和fiddler配置的一样!


开启fiddler,安装证书——打开模拟器浏览器 输入IP地址:端口号 如:192.168.1.9:8889,选择第二个蓝颜色的来连接点击

下载完,安装重命名即可
测试一下,在上面步骤全部完成的情况下,打开浏览器数据百度网址,看看fiddler是否抓到包如果是下图这样的就可以了
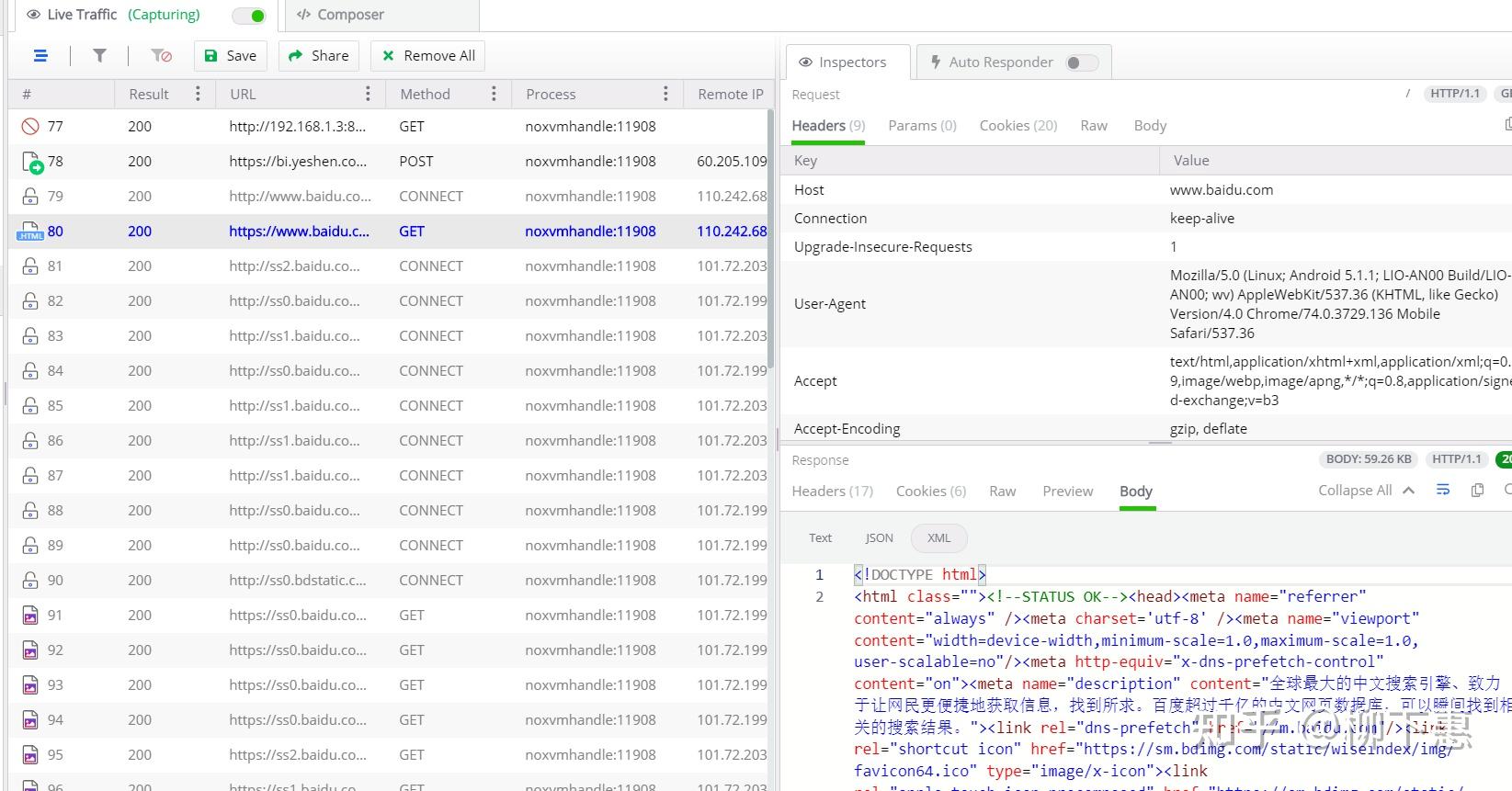
(3)mitmdumpy下载
直接命令行pip即可,这个简单如果出现问题百度一下,对了还有CA证书也需要安装
目的:获取视频下载的真实接口
打开fiddler 手机模拟器手机抓包——进入一个小姐姐的主页,进入之后就可以停止flddler的抓包了
大家可以看到我们的fiddler为我们抓包到了很多的数据包啊,最笨的办法一条一条的点开的看,最简单的办法通过筛选找到这个小姐姐主页的数据,那怎么筛选呢? 点击fiddler中URL列旁边的三个点,输入aweme.snssdk.com/aweme/v1/aweme/post/?,点击fiddler即可,那输入的是什么呢?我可告诉大家 那是我一条一条找之后发现的主页数据URL的特征,通过他就能筛选出主页数据包
我们筛选一下,可以看到啊只有一条数据包,我们点击右下角的Body-JSON看一下,可以看到啊,这正是我们想要的主页数据包
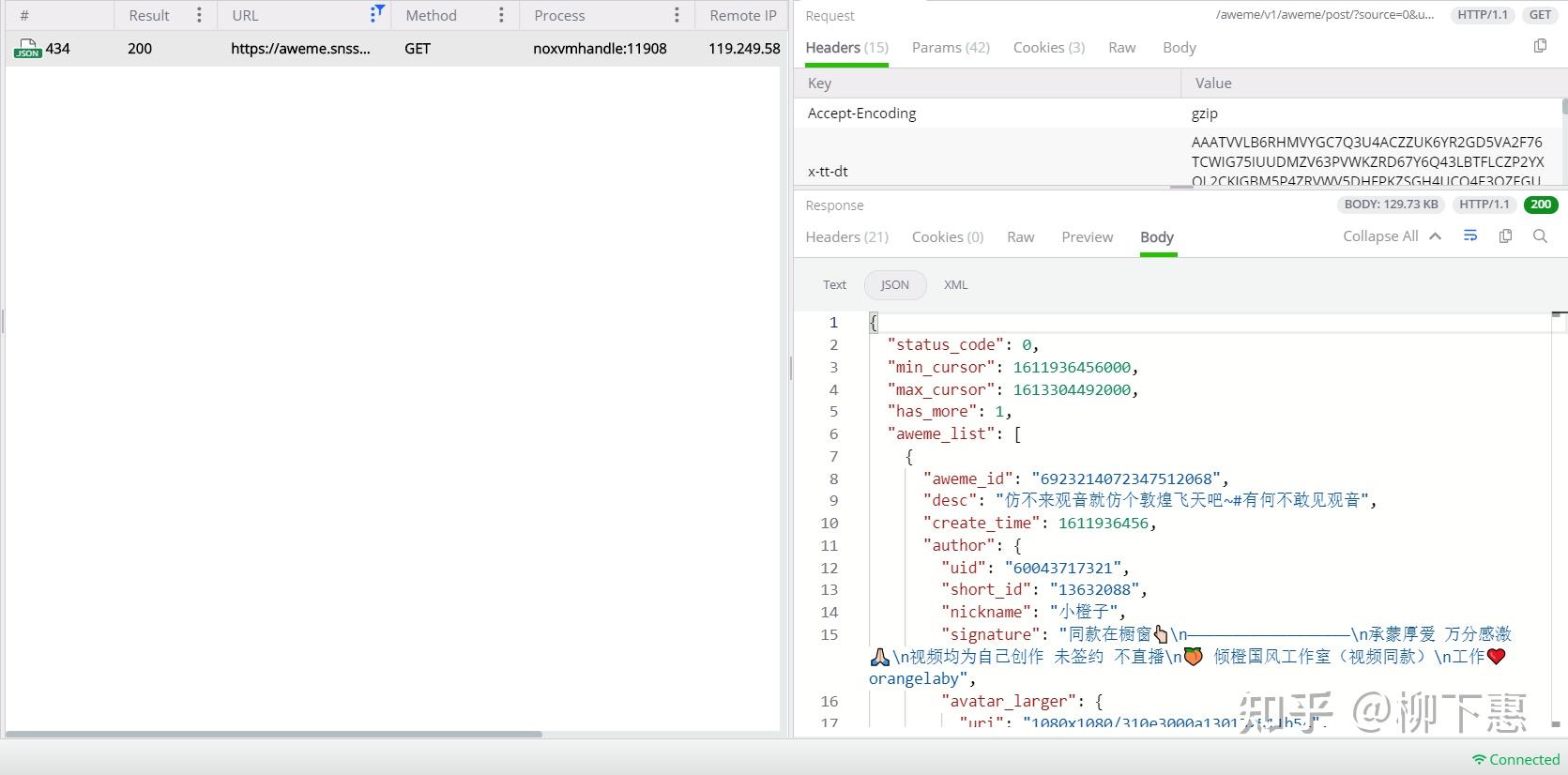
我们把他的text右键全选复制一下,进入json网站转换一下
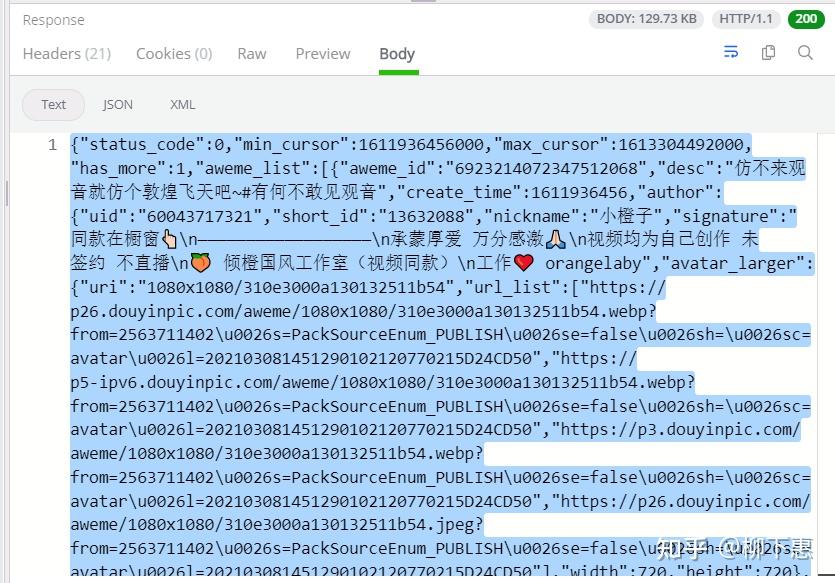
对其折叠后得到的就是这样的数据,大家看一下啊 他是有规律的,研究一下,我就直接告诉你了,他的aweme_list中有N个object,每个object就是每个视频对应的数据

我们点开其中一个object找一下视频的连接,我就直接告诉你了,这没什么技术含量,他是视频链接 按说得和video沾边吧,事实就是如此,object下的video中的第一个playaddr中urllist里的链接就是视频下载链接,有四个都一样
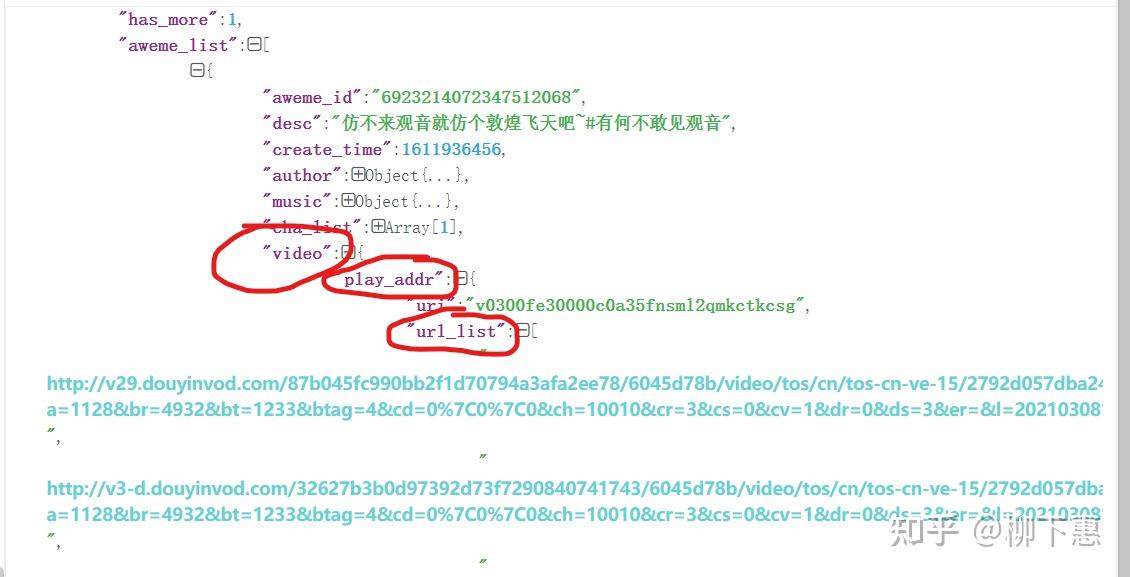
到底是不是呢,我们点开一下看看,点开之后发现他是一个下载链接,而下载的是一个html文件,
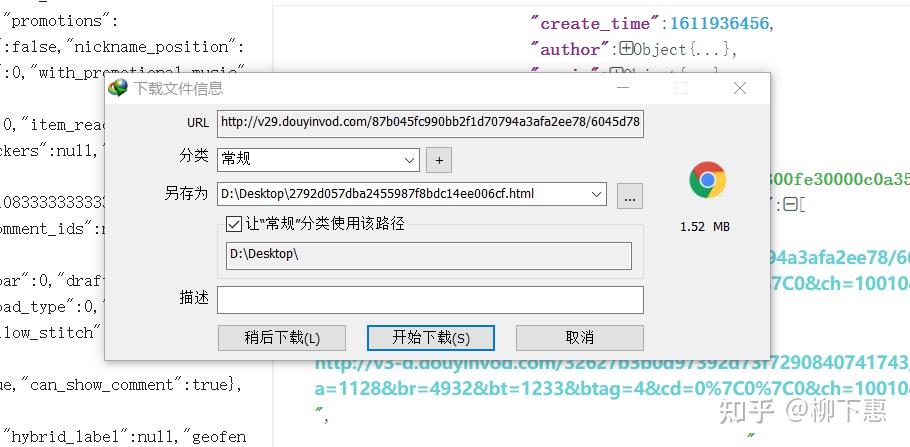
先别急 我们把它下载下来,再把他的文件后缀名 改成MP4(直接开 没有技术含量),你在看他这个文件点开他 你会看到特就是主页中的视频 而且无水印
那好,到这里 fiddler的作用已经结束了,我们获得了什么呢,我们知道了通过aweme.snssdk.com/aweme/v1/aweme/post/?可以找到主页视频数据,发现了视频下载的url就在awemelist-video-playaddr-urllist中。
目的:获得视频下载链接并保存
在执行mitmdump抓包之前呢,我们需要写一个python文件了,这个脚本的作用就是将视频的下载链接解析处理并保存。那如何调用这个脚本呢,就是得通过mitmdump调用,mitmdump和fiddler的不同之处就在于mitmdump可以调用python文件
那如何来写呢,思路很简单 我们已经知道了主页数据的url特征,我们可以用类似于fiddler筛选的方式利用mitmdump筛选出主页数据,通过主页数据就可以解析除视频真实下载链接,代码如下,需要注意的是response(flow)这个函数必须这样命名这样写,这个函数是用于和mitmdump交互的
def parser_home(parser_home):
data=[]
home_data=json.loads(parser_home)
for item in home_data["aweme_list"]:
dic = {}
dic["video_url"]=item["video"]["play_addr"]["url_list"][3] #视频下载链接
data.append(dic)
return data
def save_data(data,path):
header = list(data[0].keys()) # 数据列名
with open(path, 'a', newline='',encoding="utf-8") as f:
writer = csv.DictWriter(f,fieldnames=header)
writer.writerows(data)
def response(flow):
try:
if "aweme.snssdk.com/aweme/v1/aweme/post/?" in flow.request.url:
data=parser_home(flow.response.text)
save_data(data,"home.csv")
except:
print("---"*100,"错误","--"*100)
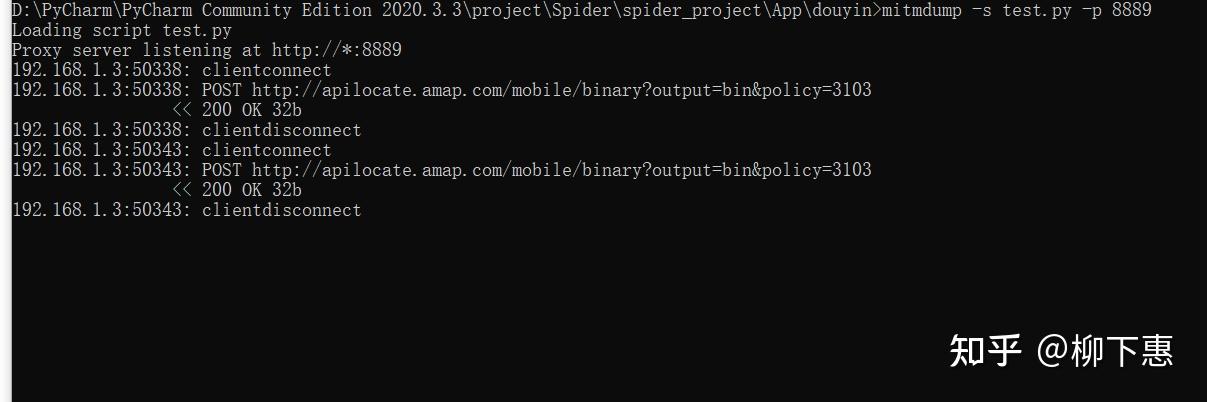
pass写好文件之后就该调用了,首先命令行进入写好的py的目录下 通过 mitmdump -s test.py -p 8889 调用 -s后是py文件名 -p后是端口号 必须跟手机上的一模一样 和fiddler设置一样。看到下面的就对了
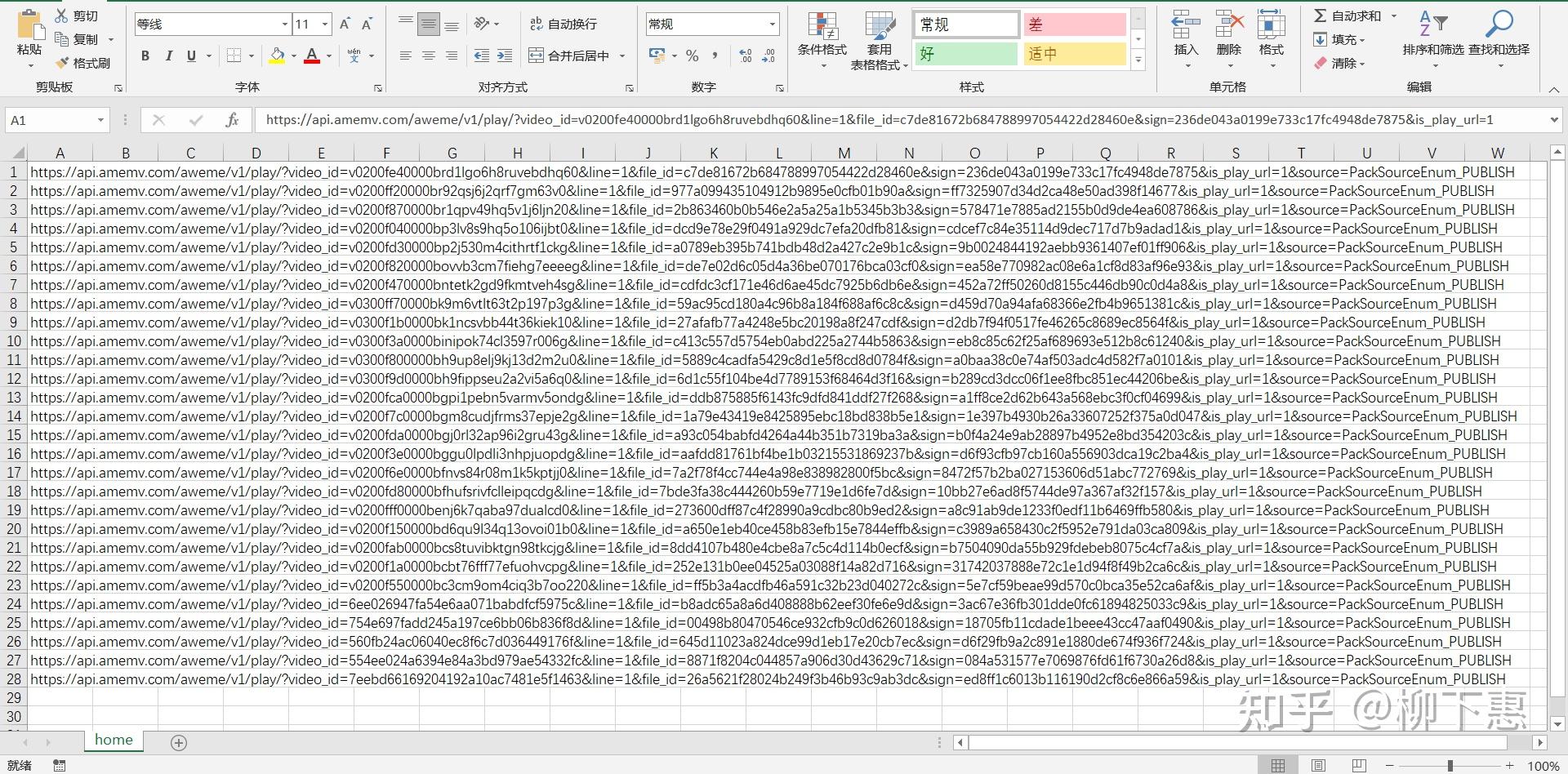
我们用手机打开抖音搜索一个小姐姐,打开主页,如果你写的py跟我的一样那么在你指定就生成了一个csv文件 是下面的样子
从mitmdump开始我是发布了一个视频的可以去我主页看这个视频,很这个情况啊 基本上是差不多的,流程是没毛病的
我们已经拿到了视频的下载地址那么现在通过Python下载我想应该不是难事吧 直接上代码了
def Download_video(url):
video = requests.get(url).content
path_vi = (r"D:/Desktop/视频/%s.mp4"%(random.randint(0,100000)))
with open(path_vi, "wb") as code:
code.write(video)
if __name__ == "__main__":
if not os.path.exists(r"D:/Desktop/视频"):
os.mkdir(r"D:/Desktop/视频")
df = pd.read_csv("home.csv", names=["url"])
pool=Pool(5)
pool.map(Download_video,df.url.tolist())然后就有了开头的视频了。我之前录了一个视频也是抓包下载视频的 在我发布的视频,流程跟这个是差不多的要是觉得文字有些难理解可以去看看视频。都看到这了,还不点个赞收个藏想啥呢


